この記事での学習内容 基本情報 応用情報
バッチ処理などで使用される整列処理、併合処理、コントロールブレイク処理、編集処理のアルゴリズムを理解する。
ファイル処理のアルゴリズム
ファイル処理とは、入力装置や外部記憶装置から読み取ったファイルを処理することです。処理対象のデータが主記憶装置の中にないため、以下のような手順が基本となります。
- 前処理: ファイルを開き、内容を主記憶装置の中に展開します。
- 主処理: 開いたファイルに対して、1レコードずつ所定の処理を行います。
- 後処理: ファイルを閉じます。
なお、ここでいうファイルは以下の定義となります。
- レコード: 型の異なる幾つかの項目(=フィールド)を持つ
- ファイル: 同じフィールドを持つレコードの集まり
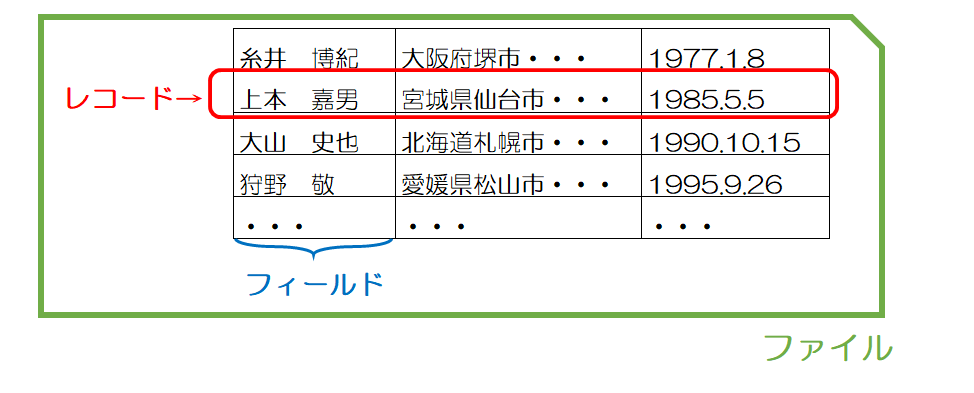
ファイルの性質として、データ件数が膨大になることがあるため、ハードディスクなどの外部記憶装置に作業ファイルを作成し、中間結果を一時退避しながら処理をすすめることもある。その場合、外部記憶装置に十分な空き容量が必要となる。
ファイルの併合処理
ファイルの併合処理は、二つの整列済みのレコードの並びで構成されるファイルを、一つの整列されたレコードのファイルにする処理です。
例:ファイルAとBから、ファイルCを作成する
- 前処理: ファイルA、B、Cをそれぞれ開く。
- 主処理: ファイルA、Bを1レコードずつ読み込み、値の小さい方のレコードをファイルCに出力し、出力した方のファイルの次のレコードを読み込む。
これを両ファイルの終端まで繰り返す。 - 後処理: ファイルA、B、Cをそれぞれ閉じる。
コントロールブレイク処理
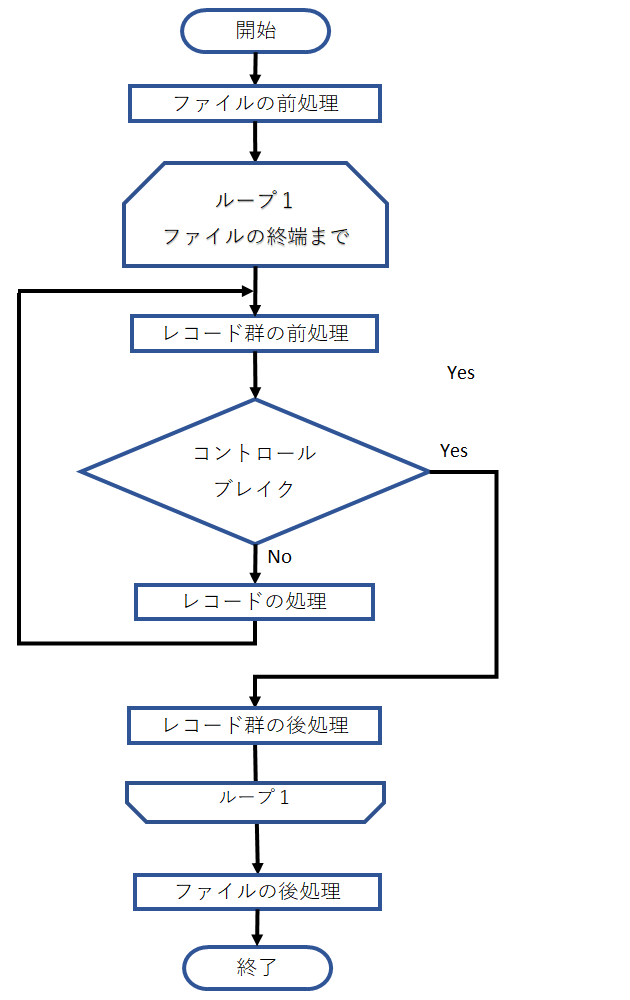
コントロールブレイクとは、同じキー値を持つレコード軍の切れ目のことです。
コントロールブレイク処理とは、コントロールブレイクに出会ったらそのレコード群の処理を終了し、複数のレコード群の処理を反復することです。レコード群の中のレコードごとの処理の反復とあわせて、二重の反復になります。
例:社員の給与の部署ごとの合計
- 社員の給与一覧ファイルをあらかじめ部署で整列
- 部署が同じである間、社員毎の給与を計算用変数に加算していく。
- 違い部署コードが出現したら「コントロールブレイク」
部署名と計算用変数の値を中間ファイルに出力し、計算用変数0で初期化。 - 2と3をファイルの終端まで繰り返す。
- ファイル終端まで来たら、部署名と計算用変数の値を中間ファイルに出力。中間ファイルの内容を処理の最終結果として書き出す。
ファイルの編集処理
ファイルの編集処理は、既存のファイルのデータを修正する処理です。
- 前処理: マスターファイルM、トランザクションファイルT、新マスターファイルNを開く。
- 主処理: ファイルMとファイルTからから1レコードずつ読み込み、キー値を比較して以下の処理を行う。これをファイル終端まで繰り返す。
- Tのキー値=Mのキー値なら、ファイルTのレコードをファイルNに出力し、ファイルMとファイルTの次のレコードを読み込む。(データの更新)
- Tのキー値>Mのキー値なら、ファイルMのレコードをファイルNに出力し、ファイルMの次のレコードを読み込む。
- Tのキー値<Mのキー値なら、ファイルTのレコードをファイルNに出力し、ファイルTの次のレコードを読み込む。(レコードの追加)
- 後処理: ファイルM、ファイルT、ファイルNを閉じる。