この記事での学習内容 基本情報 応用情報
コンパイラの役割、コンパイルの過程、字句解析、構文解析、最適化の基本的な考え方、仕組みを理解する。
用語例:文脈自由文法、意味解析、コード生成、中間言語、目的プログラム、形式言語、オートマトン
言語プロセッサ
コンピュータが直接実行できるプログラムは「機械語」のプログラムです。
機械語のプログラムは、人間がみると単なる数値(2進数)の並びで、人間が作成したり呼んだりするのには不向きです。
そのため、人間がプログラムを扱いやすくするために、プログラミング言語が存在します。プログラミング言語で書かれたプログラムのことを「ソースコード」あるいは「原始プログラム」と呼びます。
「ソースコード」はそのままではコンピュータ上で実行することは出来ません。実行可能な機械語のプログラムに変換することが必要になります。この変換処理を行うのが「言語プロセッサ」と呼ばれるものです。
言語プロセッサにはいくつかの種類があります。
- アセンブラ: 機械語と1対1に対応したアセンブラ言語を機械語に変換するプログラム
- コンパイラ: ソースコードを一括して機械語に変換するプログラム
- インタプリタ: ソースコードを機械語に変換しながら実行するプログラム
- ジェネレータ: 必要な条件をパラメータで支持することで、目的に応じたプログラムを自動生成するプログラム
コンパイラ理論
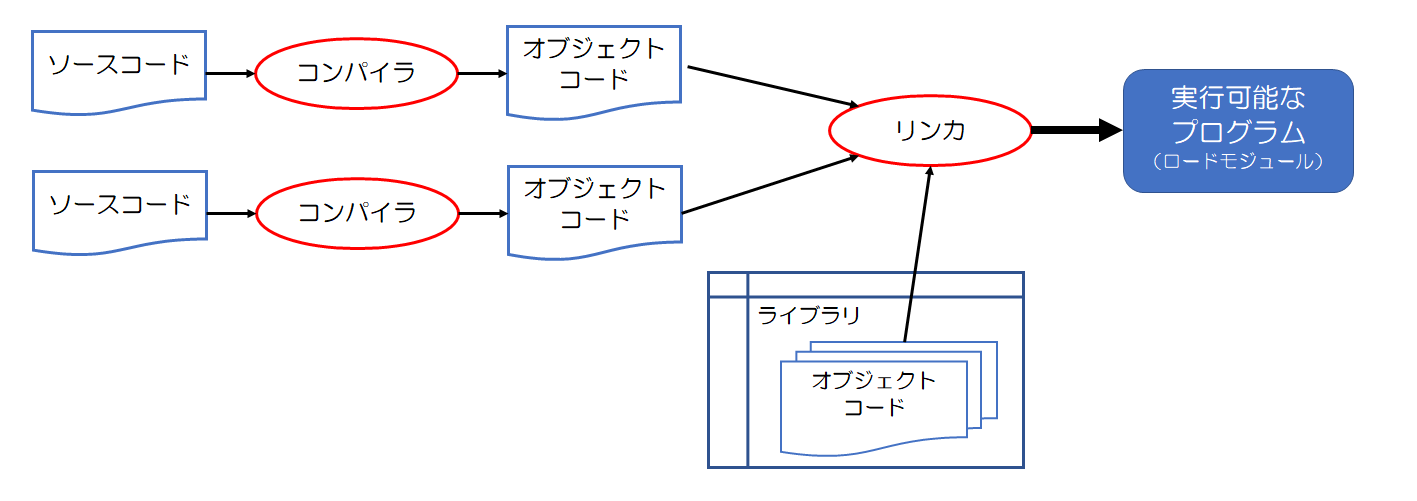
コンパイラで実行可能なプログラムを生成する場合、直接実行可能なプログラムを生成するわけではありません。これは、大規模なプログラムになると、一つのプログラムのソースコードを複数に分けて扱う必要が出てくるからです。
実行可能なプログラムを生成する第一段階は、ソースコードを変換して「オブジェクトコード」または「目的プログラム」を生成することです。
この「オブジェクトコード」はソースコード単位で作られます。
第二段階として、オブジェクトコードをつなげて実行可能なプログラムを生成します。
この段階では、ライブラリと呼ばれるオブジェクトコードの集合体が使われることもあります。
ライブラリは多くのプログラムで使われるであろう、ファイル入出力などの機能をあらかじめオブジェクトコードとして用意しておいたものです。
なお、第二段階で使われるプログラムのことを「リンカ」または「リンケージエディタ」とも呼びます。
コンパイラの処理手順
コンパイラがソースコードからオブジェクトコードを生成する時、いくつかの段階を経て処理が行われます。
典型的な流れは、字句解析→構文解析→意味解析→最適化→コード生成、となっています。
- 字句解析: ソースコードを最小の単位の語句(トークン)に分解
- 構文解析: トークンの並びを、定められた文法に従って解析
- 意味解析: トークンの意味を考慮した解析
- 最適化&コード生成: プログラムの高速化、サイズの縮小